










Wer kennt das nicht, eine Excel-Datei landet im Posteingang, hunderte Zeilen mit Firmennamen, aber die entscheidenden Informationen fehlen. Mitarbeiterzahlen? Unbekannt. Umsätze? Fehlanzeige. Geschäftsfelder? Nebulös. Genau diese Situation erlebte ich vor einigen Wochen, als 500 Kundendatensätze auf meinem Schreibtisch landeten. Was früher tagelange Recherche bedeutet hätte, konnte ich mit einem selbstgebauten KI-Werkzeug in wenigen Minuten erledigen. Der Weg dorthin führte über einige Umwege, die sich am Ende aber als lehrreich erwiesen.
Die Ausgangslage war typisch für viele Unternehmen. 500 Datensätze mit Kundennamen sollten nach ihrer Bedeutung für ein bestimmtes Thema gefiltert werden. Ohne zusätzliche Informationen über diese Unternehmen war das allerdings unmöglich. Die naheliegende Lösung wäre gewesen, jeden einzelnen Firmennamen in die Suchmaschine einzutippen, relevante Webseiten zu durchforsten und die gefundenen Daten manuell in die Excel-Tabelle zu übertragen. Bei 500 Einträgen und geschätzten fünf Minuten pro Datensatz wären das über 40 Stunden stupider Handarbeit gewesen.
Die ersten Gehversuche mit ChatGPT
Der erste Versuch lag nahe, warum nicht ChatGPTs Deep Research nutzen, um gleich mehrere Unternehmen auf einmal zu untersuchen? Die Hoffnung war groß, dass die KI einfach 20 Firmennamen auf einmal verarbeiten und sauber getrennte Ergebnisse liefern würde. Doch die Ernüchterung folgte schnell. Die KI vermischte Informationen verschiedener Unternehmen, verwechselte ähnlich klingende Namen und produzierte ein Durcheinander, das mehr Verwirrung als Klarheit stiftete. Bei der Fülle an Daten schien die KI den Überblick zu verlieren, Quellen wurden falsch zugeordnet, und die Ergebnisse waren praktisch unbrauchbar. Aber was passiert, wenn man nur ein einziges Unternehmen recherchieren lässt? Das Ergebnis überraschte positiv. Die KI lieferte präzise, gut recherchierte Informationen mit korrekten Quellenangaben. Die Datenqualität war hervorragend, solange man ihr nur eine Aufgabe gleichzeitig stellte. Doch damit war das ursprüngliche Problem nur verschoben. Jetzt musste man zwar nicht mehr selbst recherchieren, aber immer noch 500 Mal denselben Vorgang wiederholen. Das Chat-Interface von ChatGPT wurde damit zum Flaschenhals.
Die Geburt einer automatisierten Lösung
Hier kam die Idee ins Spiel, die den Durchbruch brachte. Warum nicht die Stärken der KI nutzen und gleichzeitig ihre Schwächen umgehen? Statt eines großen Auftrags würden viele kleine, parallel ablaufende Anfragen das Problem lösen. Die OpenAI-API machte genau das möglich. Ich entwickelte einen eigenen Bot, der zehn Anfragen gleichzeitig an die Schnittstelle schickt, dabei für jede Anfrage die Web-Recherche-Funktionen nutzt und die Ergebnisse sauber getrennt zurückliefert. Die technische Umsetzung erwies sich als erstaunlich unkompliziert. Mit Cursor als "Entwicklungsumgebung" entstand Step für Step ein Werkzeug, das genau diese Parallelverarbeitung beherrschte. Gewissermaßen eine KI, die dabei hilft, eine andere KI zu steuern. Die Ironie war nicht zu übersehen. Ich nutzte künstliche Intelligenz, um künstliche Intelligenz zu programmieren, die wiederum künstliche Intelligenz nutzt, um Daten zu recherchieren.
Die Tücken der Detailarbeit
Natürlich war damit noch nicht alles gelöst. Die ersten Testläufe zeigten schnell, dass die KI zwar fleißig Informationen sammelte, aber nicht immer die richtigen. Mal wurden veraltete Mitarbeiterzahlen ausgegeben, mal Umsätze aus dem falschen Geschäftsjahr. Besonders bei Konzernen mit vielen Tochterunternehmen oder bei Firmennamen, die in verschiedenen Ländern vorkommen, produzierte das System fehlerhafte Ergebnisse.
Hier kam eine alte Bekannte wieder ins Spiel, die viele schon totgesagt hatten, die Kunst des Prompt-Engineerings. Es zeigte sich, dass präzise formulierte Anweisungen den Unterschied zwischen brauchbaren und unbrauchbaren Ergebnissen ausmachten. Die KI musste lernen, aktuelle von veralteten Daten zu unterscheiden, Konzernmütter von Töchtern zu trennen und bei mehreren gleichnamigen Unternehmen das richtige zu identifizieren. Jede dieser Herausforderungen erforderte eine Anpassung der Eingabeaufforderung.
Nach etlichen Durchläufen und stetiger Verfeinerung entstand ein Prompt, der zuverlässig funktionierte. Er enthielt klare Anweisungen zur Priorisierung aktueller Quellen, zur Unterscheidung verschiedener Unternehmenseinheiten und zur Behandlung von Sonderfällen. Was sich in meiner Arbeit mit KI-Systemen über die letzten zwei Jahre angesammelt hatte, zahlte sich nun aus.
Das fertige Werkzeug in der Praxis
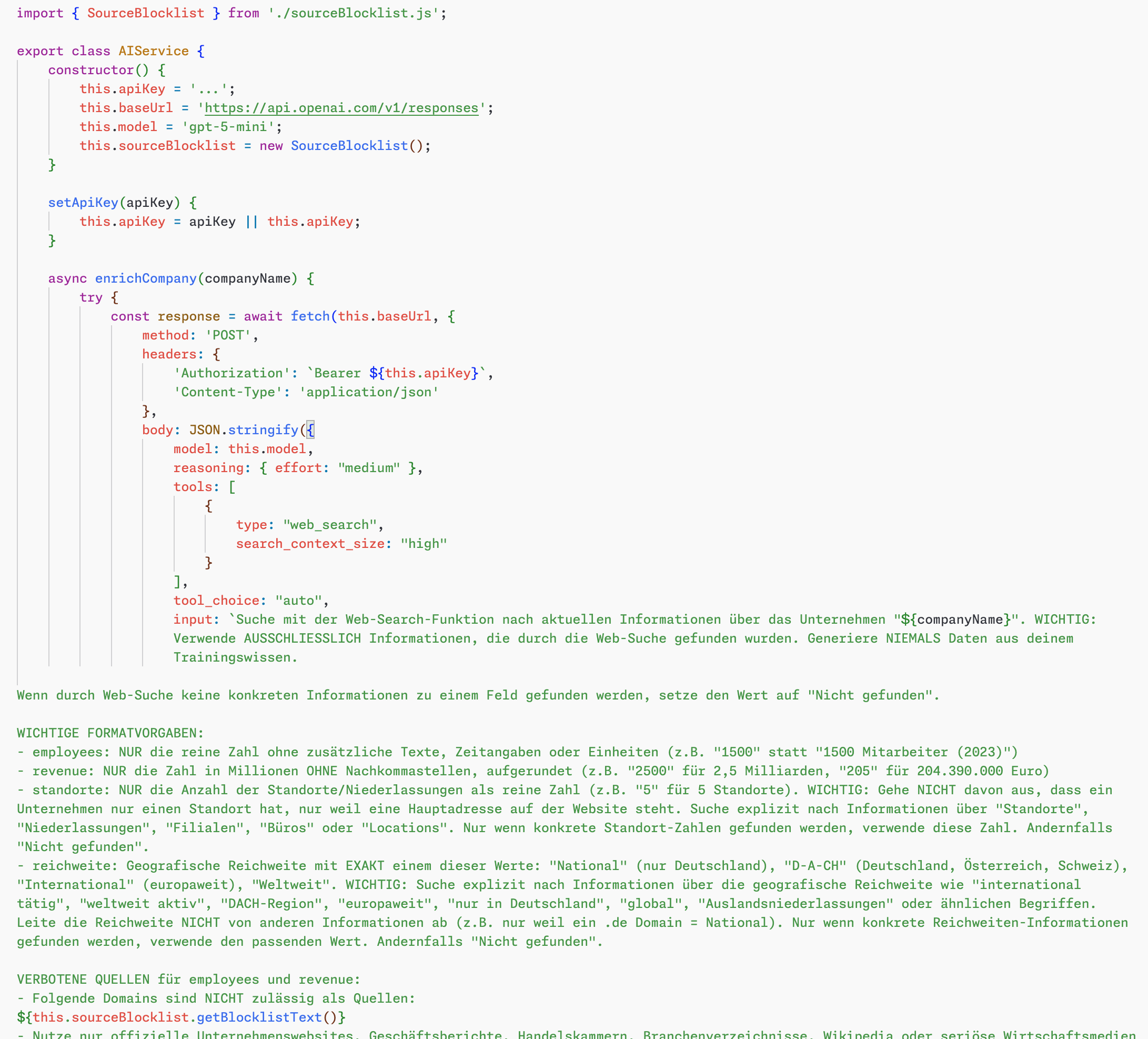
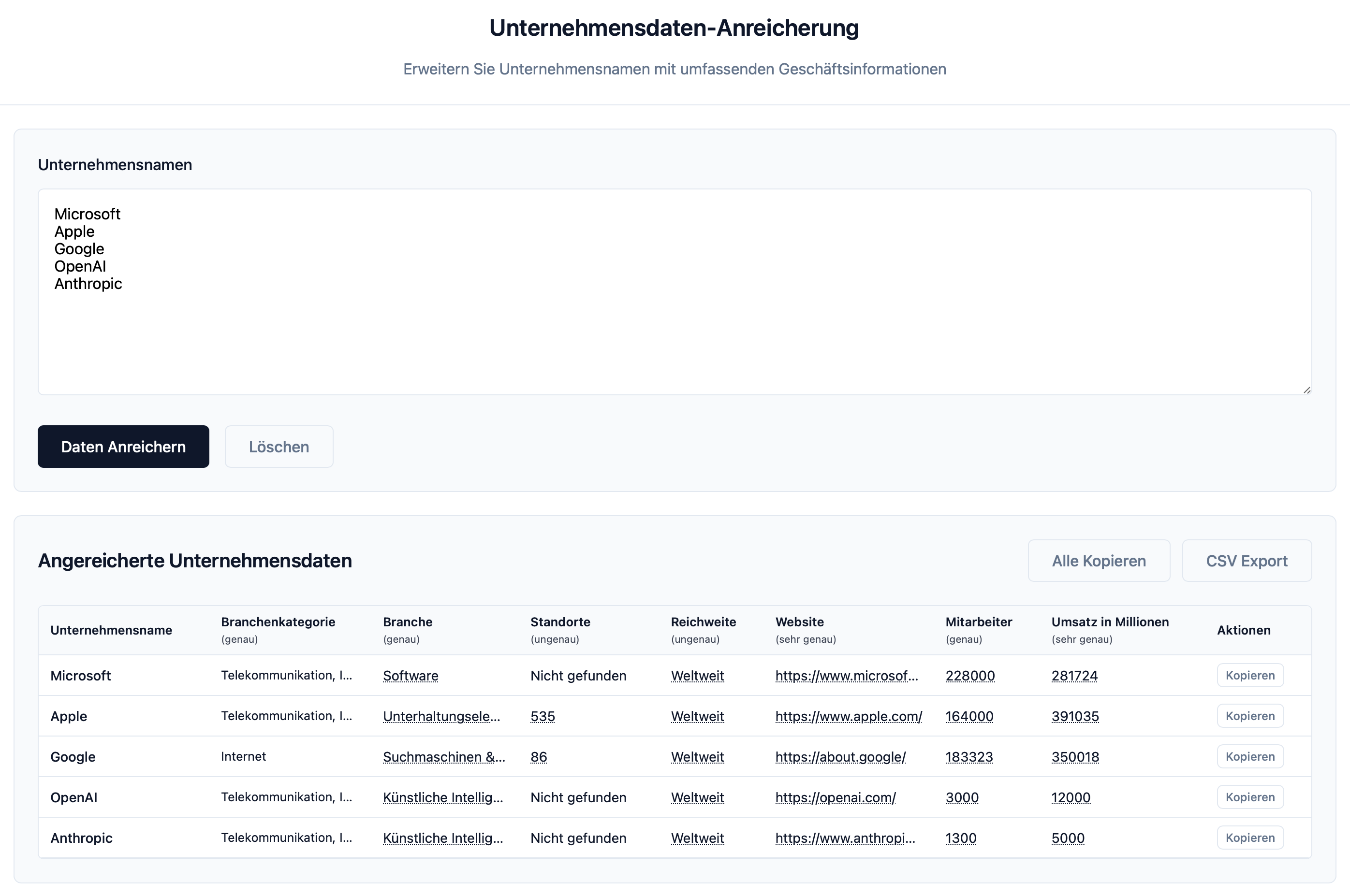
Das Endergebnis ist ein Werkzeug, das beliebig viele Unternehmensnamen entgegennimmt und für jeden davon eine Recherche durchführt. Die Bedienung könnte einfacher nicht sein. Im Frontend wirft man die Firmennamen hinein, wählt aus, welche Informationen man benötigt, und wartet, während die KI ihre Arbeit macht. Nach einigen Minuten spuckt das System für jedes Unternehmen die gewünschten Daten aus, sei es die Mitarbeiterzahl, der Jahresumsatz, die Hauptgeschäftsfelder oder andere relevante Kennzahlen.
Die technische Basis bildet dabei das GPT-5-Mini-Modell, das mit mittlerer Reasoning-Stufe arbeitet und das Such-Werkzeug in der höchsten Qualitätsstufe nutzt. Diese Konfiguration hat sich als optimaler Kompromiss zwischen Geschwindigkeit, Kosten und Ergebnisqualität erwiesen. Schnellere Einstellungen lieferten zu oberflächliche Ergebnisse, während aufwendigere Konfigurationen die Kosten in die Höhe trieben, ohne merklich bessere Resultate zu produzieren.
Die Kostenfrage und andere Fallstricke
Natürlich hat die Sache einen Haken, sogar mehrere.
- Der offensichtlichste sind die Kosten. Mit etwa drei Cent pro recherchiertem Datensatz summiert sich das bei großen Datenmengen schnell. Bei den ursprünglichen 500 Firmennamen wären das 15 Euro. Ob sich das lohnt, muss jeder selbst entscheiden. Im Vergleich zu 40 Stunden manueller Arbeit relativiert sich dieser Betrag allerdings schnell. In meinem Fall war die Entscheidung klar, die eingesparte Zeit war weitaus wertvoller als die API-Kosten.
- Ein weiterer wichtiger Punkt betrifft die Datenqualität. Die KI kann nur finden, was auch tatsächlich öffentlich zugänglich im Internet steht. Bei kleinen Unternehmen ohne Webpräsenz oder bei Firmen, die ihre Geschäftszahlen nicht veröffentlichen, stößt das System an seine Grenzen. Hier hilft auch die beste Prompt-Optimierung nicht weiter. Man muss sich bewusst sein, dass man mit öffentlich verfügbaren Informationen arbeitet, die möglicherweise unvollständig oder veraltet sein können.
- Auch die Verlässlichkeit der gefundenen Informationen bleibt ein Thema. Die KI neigt dazu, Lücken mit plausibel klingenden, aber falschen Angaben zu füllen. Deshalb war es wichtig, den Prompt so zu gestalten, dass die KI lieber "keine Information gefunden" meldet, als zu raten. Diese Ehrlichkeit musste regelrecht antrainiert werden, da die Modelle von Haus aus darauf getrimmt sind, immer eine Antwort zu liefern.
Der Zeitaufwand und die Lernkurve
Die Entwicklung des kompletten Werkzeugs dauerte etwa vier Stunden. Das mag nach viel klingen für ein Tool, das zunächst nur eine Excel-Liste abarbeiten sollte. Doch diese Zeit verteilte sich auf verschiedene Aspekte
- das Design der Benutzeroberfläche, die Recherche der API-Einstellungen,
- die Entwicklung des Konzepts,
- die technische Umsetzung und natürlich das ausgiebige Testen und Verfeinern der Prompts.
Der eigentliche Wert liegt aber nicht nur im fertigen Werkzeug. Die während der Entwicklung gesammelten Erfahrungen fließen in zukünftige Projekte ein. Das Verständnis dafür, wie man KI-APIs effektiv nutzt, wie man mit Parallelverarbeitung umgeht und wie man Prompts für spezifische Aufgaben optimiert, ist unbezahlbar. Zudem ist das Tool nicht auf diese eine Aufgabe beschränkt. Es lässt sich für beliebige Datenanreicherungsaufgaben einsetzen, sei es für Marktanalysen, Wettbewerbsbeobachtung oder Kundenrecherche.
Cursor als zentrales Entwicklungswerkzeug
Die technische Umsetzung wurde durch Cursor erheblich vereinfacht. Diese KI-gestützte Entwicklungsumgebung übernahm große Teile der Programmierarbeit. Statt mühsam jede Zeile Code selbst zu schreiben, konnte ich mich auf die Konzeption und Feinabstimmung konzentrieren. Cursor generierte den notwendigen Code für die API-Anbindung, die Parallelverarbeitung und die Benutzeroberfläche. Nach Fertigstellung wurde das Werkzeug entweder auf einen Server geladen oder lokal betrieben, je nach Anforderung und Sicherheitsbedürfnis.
Die Einfachheit dieser Lösung mag überraschen. Keine komplexe Infrastruktur, keine teuren Spezialsysteme, nur ein cleverer Einsatz vorhandener Technologien. Das zeigt, dass KI-gestützte Automatisierung nicht mehr das Privileg großer Technologieunternehmen ist. Mit den richtigen Werkzeugen und etwas Experimentierfreude kann jeder seine eigenen Automatisierungslösungen bauen.
Was diese Geschichte lehrt
Diese Erfahrung zeigt mehrere wichtige Punkte.
- Der direkte Weg ist nicht immer der beste. Die anfängliche Idee, alles in einem Rutsch zu erledigen, scheiterte. Erst der Umweg über die Einzelverarbeitung führte zur funktionierenden Lösung.
- Die Grenzen der KI zu kennen ist genauso wichtig wie ihre Möglichkeiten. Nur wer weiß, wo die Technik versagt, kann Wege finden, diese Schwächen zu umgehen.
- Es zeigt sich der Wert iterativer Entwicklung. Statt zu versuchen, von Anfang an die perfekte Lösung zu bauen, führte schrittweises Verbessern zum Ziel. Jeder Testlauf brachte neue Erkenntnisse, jede Anpassung machte das System robuster. Diese Art des Vorgehens, bei der man aus Fehlern lernt und ständig nachjustiert, erwies sich als der Schlüssel zum Erfolg.
- Es wird deutlich, dass die oft totgesagte Prompt-Optimierung weiterhin ihre Berechtigung hat. Während viele glauben, dass moderne KI-Modelle so intelligent sind, dass man nicht mehr auf die Formulierung achten muss, zeigt die Praxis das Gegenteil. Präzise Anweisungen machen den Unterschied zwischen brauchbaren und nutzlosen Ergebnissen.
Der Blick nach vorn
Solche selbstgebauten Automatisierungswerkzeuge werden in Zukunft immer wichtiger. Die Menge an Daten wächst stetig, während die Zeit für deren Verarbeitung gleich bleibt oder sogar schrumpft. Wer in der Lage ist, sich eigene Werkzeuge zu bauen, die repetitive Aufgaben übernehmen, verschafft sich einen erheblichen Vorteil. Dabei muss man kein Programmierer sein. Werkzeuge wie Cursor demokratisieren die Softwareentwicklung. Sie ermöglichen es auch Menschen ohne tiefe technische Kenntnisse, funktionsfähige Lösungen zu entwickeln. Die Hürde liegt nicht mehr im technischen Können, sondern im Verständnis des Problems und der kreativen Lösungsfindung.
Die hier beschriebene Lösung ist nur ein Beispiel für das, was möglich ist. Die gleichen Prinzipien lassen sich auf unzählige andere Herausforderungen anwenden. Ob es um die Auswertung von Kundenfeedback geht, die Analyse von Markttrends oder die Verarbeitung von Dokumenten. Überall dort, wo strukturierte Informationen aus unstrukturierten Quellen gewonnen werden müssen, können ähnliche Ansätze helfen.
Der Aufwand von vier Stunden Entwicklungszeit amortisiert sich schnell, wenn man bedenkt, wie viel manuelle Arbeit dadurch eingespart wird. Nicht nur bei der aktuellen Aufgabe, sondern bei allen zukünftigen ähnlichen Herausforderungen. Ein einmal entwickeltes Werkzeug kann immer wieder eingesetzt und an neue Anforderungen angepasst werden. Dieser konkrete Fall aus meinem Arbeitsalltag zeigt, dass die Investition in solche Automatisierungen sich fast immer lohnt.