










Die Begriffe fliegen durcheinander, als wären sie austauschbar. Prompt Engineering hier, Context Engineering da, und irgendwo dazwischen verschwimmt die Grenze. Dabei liegt zwischen beiden Disziplinen ein fundamentaler Unterschied, den zu verstehen darüber entscheidet, ob die Arbeit mit KI-Systemen funktioniert oder im Chaos endet.
Wer sich anschaut, wie Anthropic mit Claude umgeht oder wie OpenAI ChatGPT strukturiert, erkennt schnell ein klares Muster. Die Entwickler trennen strikt zwischen dem, was der Nutzer direkt eingibt, und dem, was das System drumherum aufbaut. Diese Trennung hat einen guten Grund, denn sie spiegelt wider, wie große Sprachmodelle tatsächlich arbeiten und welche Stellschrauben wir haben, um ihre Ausgaben zu steuern.
Was einen Prompt wirklich ausmacht
Der Prompt ist das, was in der Eingabezeile steht. Punkt. Wenn jemand "Schreib mir eine E-Mail an meinen Chef" eintippt, dann ist das der Prompt. Wenn ein Nutzer ein Bild hochlädt und dazu fragt "Was siehst du hier?", dann besteht der Prompt aus diesem Bild plus der Frage. Die Eingabemenge moderner Systeme ist enorm gewachsen, manche Modelle verarbeiten mittlerweile hunderttausende Token in einem einzigen Durchlauf. Ein Prompt kann also durchaus lang und komplex sein, mit mehreren Bildern, umfangreichen Texten oder strukturierten Daten.
Aber egal wie umfangreich diese Eingabe wird, sie bleibt eine direkte, bewusste Handlung des Nutzers. Der Prompt ist der Moment, in dem jemand sagt: "Jetzt tu bitte das hier." Es ist die explizite Anweisung, die aktive Aufforderung, der konkrete Auftrag an das System.
Der Kontext ist das unsichtbare Fundament
Während der Prompt sichtbar und offensichtlich ist, arbeitet der Kontext meist im Verborgenen. Er umfasst alles, was das Modell zusätzlich zum reinen Prompt erhält. Bei ChatGPT beginnt das schon mit dem System-Prompt, den OpenAI vorschaltet und den kein Nutzer jemals zu Gesicht bekommt. Dieser unsichtbare Pre-Prompt definiert Verhaltensregeln, Einschränkungen und grundlegende Charakteristika des Systems. Er ist der Grund, warum ChatGPT sich weigert, bestimmte Inhalte zu produzieren, oder warum es auf eine bestimmte Art antwortet.
Dann kommen die benutzerdefinierten Kontextelemente. Die Memory-Funktion von ChatGPT speichert Informationen über vorherige Gespräche und fügt sie automatisch hinzu, ohne dass der Nutzer sie explizit erwähnen muss. Ein selbst erstellter GPT bringt seinen eigenen Pre-Prompt mit, den der Ersteller festgelegt hat. Die allgemeinen Einstellungen, in denen jemand definiert, dass das System prägnant antworten oder besonders ausführlich sein soll, fließen ebenfalls ein.
Dokumente, die jemand an den Agenten (nicht Chat) anhängt, gehören zum Kontext. Eine aktivierte Websuche, die Hintergrundinformationen beisteuert, ist Kontext. Die gesamte Gesprächshistorie, die das Modell im Gedächtnis behält, bildet einen wachsenden Kontext, der mit jedem weiteren Austausch größer wird. All diese Elemente umgeben den eigentlichen Prompt wie Schichten einer Zwiebel.
Die Beziehung zwischen beiden verstehen
Hier liegt der Knackpunkt, an dem viele scheitern. Der Prompt ist immer Teil des Kontexts. Aber der Kontext ist niemals bloß ein Prompt. Diese asymmetrische Beziehung zu begreifen macht den Unterschied zwischen planlosem Herumprobieren und gezielter Steuerung aus.
Wenn jemand eine Frage stellt, dann wird diese Frage zum Teil eines viel größeren Informationspakets, das das Modell verarbeitet. Das System sieht nicht nur "Schreib mir eine E-Mail", sondern erhält gleichzeitig Anweisungen darüber, wie es sich grundsätzlich verhalten soll, Informationen aus früheren Gesprächen, eventuell angehängte Dokumente und noch vieles mehr. Der Prompt schwimmt in einem Meer von Kontextinformationen.
Wer nur am Prompt feilt und den Kontext ignoriert, optimiert an der falschen Stelle. Das ist wie das Polieren des Türgriffs, während das ganze Haus schief steht. Umgekehrt gilt aber auch, dass selbst der reichhaltigste Kontext ohne einen klaren, gut formulierten Prompt ins Leere läuft. Beide Seiten müssen zusammenpassen, doch das Verständnis für ihre unterschiedlichen Rollen ist entscheidend.
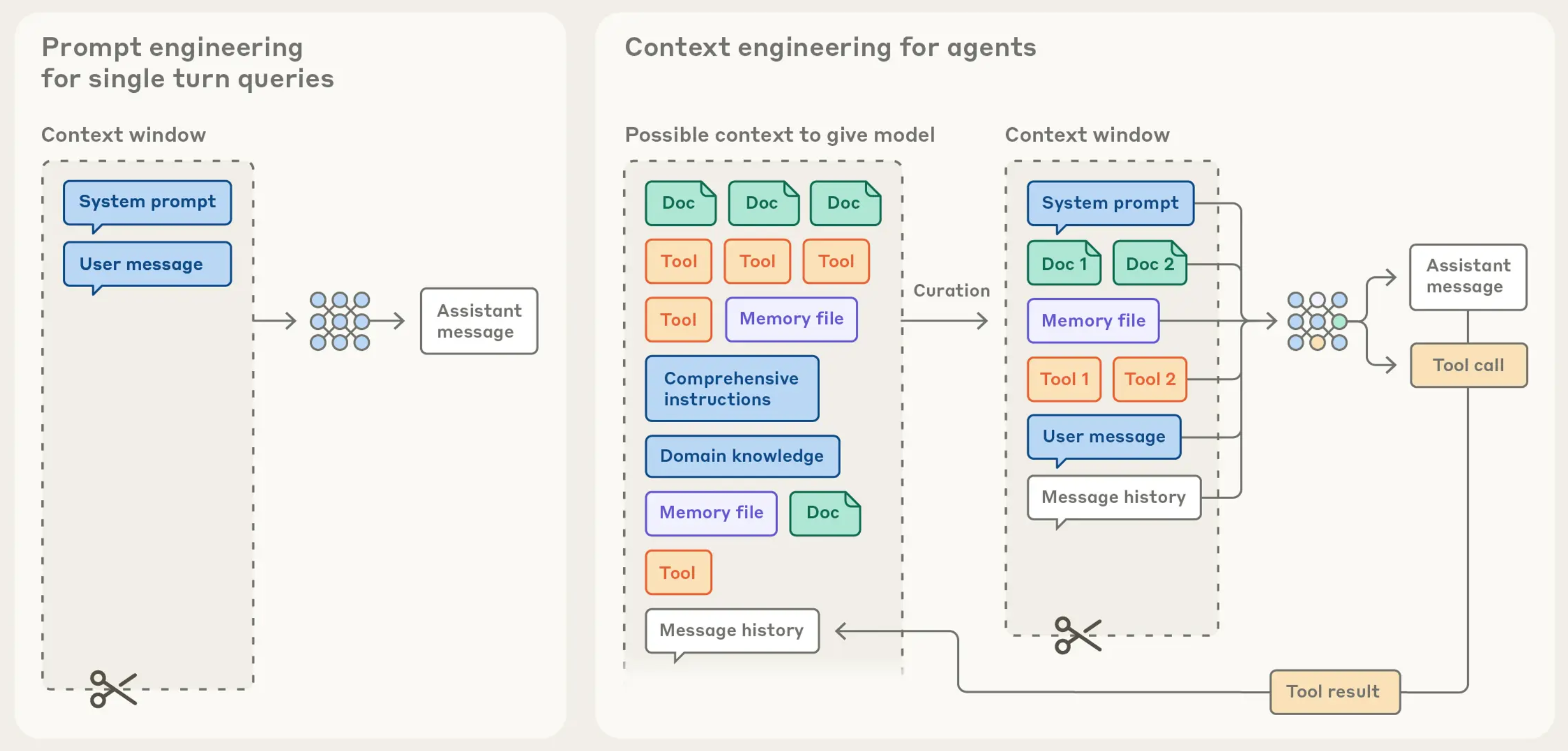
Context Engineering als systematische Disziplin
Wenn die Diskussion auf Context Engineering schwenkt, geht es um die bewusste, durchdachte Gestaltung all dieser Kontextelemente. Es bedeutet zu verstehen, welche Informationen das Modell wann benötigt und in welcher Form sie am wirksamsten sind. Anders als beim Prompt Engineering, wo es hauptsächlich um die Formulierung der direkten Anweisung geht, befasst sich Context Engineering mit der Architektur des gesamten Informationsraums. Mehr dazu bei Anthropic: "https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents"
Das beginnt bei der Entscheidung, was überhaupt in den Kontext gehört. Ein häufiger Fehler besteht darin, dem Modell zu viel zu geben. Wer zehn Dokumente anhängt, obwohl nur zwei relevant sind, verwässert die Aufmerksamkeit des Systems. Große Sprachmodelle haben zwar enorme Kontextfenster, aber das bedeutet nicht, dass sie alle Informationen gleich gewichten. Je mehr Rauschen im Kontext existiert, desto schwieriger wird es für das Modell, das Wesentliche herauszufiltern.
Die Memory-Funktion illustriert dieses Problem perfekt. Wenn sie zu viel speichert und bei jeder Anfrage irrelevante Informationen aus früheren Gesprächen einblendet, dann stört das mehr als es hilft. Das Modell muss sich durch einen Wust von Nebensächlichkeiten arbeiten, bevor es zur aktuellen Frage vordringt. Context Engineering bedeutet hier, die Memory-Funktion gezielt zu steuern, unwichtige Informationen zu löschen und nur das zu behalten, was langfristig wertvoll bleibt.
Die Balance zwischen zu viel und zu wenig
Die Herausforderung beim Umgang mit Kontext liegt in der richtigen Dosierung. Zu wenig Kontext führt zu unpräzisen, oberflächlichen oder schlichtweg falschen Antworten. Wenn das Modell nicht weiß, in welchem Fachgebiet es sich bewegt, welche Zielgruppe angesprochen werden soll oder welche Rahmenbedingungen gelten, kann es nur raten. Die Ergebnisse bleiben generisch und verfehlen oft den Kern dessen, was tatsächlich gebraucht wird.
Zu viel Kontext hat aber einen ebenso schädlichen Effekt. Modelle können zwar technisch mit riesigen Kontextfenstern umgehen, doch ihre Aufmerksamkeit verteilt sich über alle vorhandenen Informationen. Wichtige Details gehen in der Masse unter. Widersprüchliche Angaben verwirren das System. Die Verarbeitungszeit steigt, und paradoxerweise sinkt oft die Qualität der Ausgabe, weil das Modell nicht mehr klar priorisieren kann, welche Informationen wirklich zählen.
Context Engineering bedeutet deshalb, ständig abzuwägen. Welche Informationen sind essentiell? Welche helfen dem Modell, bessere Entscheidungen zu treffen? Und welche verstopfen nur den Kanal, ohne einen Mehrwert zu liefern? Diese Fragen lassen sich nicht pauschal beantworten, sondern hängen vom konkreten Anwendungsfall ab.
Praktische Konsequenzen für die Arbeit mit KI-Systemen
Wer diese Unterscheidung verinnerlicht hat, arbeitet anders mit KI-Systemen. Statt nur an der Formulierung der Frage zu feilen, wird der Blick breiter. Welcher Pre-Prompt läuft im Hintergrund? Was hat das System in seiner Memory gespeichert? Welche Dokumente sind wirklich relevant? Wie sind die allgemeinen Einstellungen konfiguriert?
Ein Beispiel verdeutlicht den Unterschied. Jemand will eine technische Dokumentation erstellen lassen. Der naive Ansatz lautet: "Schreib eine Dokumentation für Feature X." Das ist der Prompt. Ein etwas versierterer Nutzer würde den Prompt verbessern: "Schreib eine technische Dokumentation für Feature X mit Codebeispielen und Erklärungen für fortgeschrittene Entwickler." Besser, aber immer noch begrenzt.
Jemand, der Context Engineering betreibt, geht anders vor. Zunächst wird die relevante technische Spezifikation als Dokument angehängt. Dann werden in der Memory gezielt Informationen über die Zielgruppe hinterlegt: Entwickler mit fünf Jahren Erfahrung, die bereits Framework Y kennen. Ein Custom GPT mit einem Pre-Prompt, der das System auf technische Dokumentation spezialisiert, kommt zum Einsatz. Die Einstellungen werden so angepasst, dass das Modell strukturiert und ausführlich antwortet. Erst dann kommt der Prompt: "Erstell die Dokumentation." Der Prompt selbst kann sogar kürzer sein als im zweiten Beispiel, weil der Kontext die Arbeit übernimmt.
Websuche und dynamischer Kontext
Die Integration von Websuche fügt eine weitere Dimension hinzu. Wenn ChatGPT eine Websuche durchführt, erweitert sich der Kontext dynamisch. Das System holt sich Informationen aus dem Internet und fügt sie dem Kontext hinzu, bevor es antwortet. Das ist weder Teil des ursprünglichen Prompts noch des statischen Kontexts, sondern eine aktive Kontexterweiterung während der Verarbeitung.
Hier wird Context Engineering besonders anspruchsvoll. Wann macht eine Websuche Sinn? Wenn jemand nach aktuellen Ereignissen fragt, ist sie unerlässlich. Bei rein konzeptionellen Fragen kann sie aber ablenken, weil das Modell möglicherweise irrelevante Quellen findet und einbezieht. Die Entscheidung, wann die Websuche aktiviert sein soll und wann nicht, gehört zum strategischen Umgang mit Kontext.
Dasselbe gilt für angehängte Dokumente. Ein PDF mit hundert Seiten mag technisch verarbeitbar sein, aber führt es zu besseren Ergebnissen? Manchmal ja, manchmal verschlimmert es die Situation. Context Engineering bedeutet zu testen, zu messen und zu verfeinern. Es ist ein iterativer Prozess, keine einmalige Einstellung.
Die Empfehlungen der großen Anbieter
Sowohl Anthropic als auch OpenAI haben in ihren Dokumentationen klare Hinweise darauf, wie Kontext und Prompt zusammenspielen. Claude erlaubt es beispielsweise, den System-Prompt explizit zu setzen, was Nutzern mehr Kontrolle über diese wichtige Kontextebene gibt. OpenAI strukturiert die Dinge mit seinem Custom GPT-Konzept, bei dem Pre-Prompts und Wissensdatenbanken klar getrennt vom User-Input verwaltet werden.
Diese Strukturierung ist kein Zufall. Die Entwickler haben erkannt, dass die Vermischung von Kontext und Prompt zu schlechteren Ergebnissen führt. Wenn jemand in jeden einzelnen Prompt alle Kontextinformationen packen muss, wird es schnell unhandlich. Besser ist es, stabile Kontextelemente einmal zu definieren und dann mit prägnanten Prompts zu arbeiten.
Die Empfehlung lautet daher, verschiedene Ebenen zu nutzen. System-Prompts für grundsätzliche Verhaltensweisen. Memory oder Wissensdatenbanken für faktenbasierte Informationen. Einstellungen für stilistische Präferenzen. Und dann erst der eigentliche Prompt für die konkrete Aufgabe. Diese Schichtung macht das System wartbar, nachvollziehbar und vor allem effektiv.
Fehler beim Umgang mit Kontext
Ein klassischer Fehler besteht darin, wichtige Kontextinformationen im Prompt zu vergraben. Jemand schreibt einen langen Prompt, der mit "Du bist ein erfahrener Marketing-Experte, der sich auf B2B-Software spezialisiert hat und..." beginnt. Diese Rollendefinition gehört nicht in den Prompt, sondern in den Pre-Prompt oder die System-Anweisungen (z.B. im GPT), falls möglich. Im Prompt selbst sollte nur die konkrete Aufgabe stehen.
Ein anderer Fehler liegt im gedankenlosen Anhäufen von Kontextmaterial. Wer alle verfügbaren Dokumente anhängt, alle Memory-Einträge aktiviert lässt und gleichzeitig die Websuche einschaltet, überflutet das System. Das Modell versinkt in Informationen und produziert entweder generische Antworten, die allen Quellen gerecht werden wollen, oder es pickt sich zufällig etwas heraus.
Dann gibt es noch das Gegenteil, den zu minimalistischen Ansatz. Wer glaubt, ein perfekt formulierter Prompt reiche aus und Kontext sei überflüssig, ignoriert die Realität. Modelle brauchen Orientierung. Sie brauchen Rahmen. Ein Prompt in einem Vakuum kann nicht dieselbe Qualität erreichen wie ein Prompt in einem sorgfältig kuratierten Kontext.
Context Engineering in der Praxis anwenden
Die praktische Umsetzung beginnt mit Inventur. Welche Kontextelemente stehen zur Verfügung? Bei ChatGPT sind das System-Prompts, Custom GPTs, Memory-Einträge, angehängte Dokumente, Websuche und die Gesprächshistorie. Bei Claude sind es System-Prompts, Projekte und hochgeladene Dokumente. Jedes System hat seine eigenen Mechanismen.
Der nächste Schritt ist die strategische Zuordnung. Was gehört auf welche Ebene? Informationen über den eigenen Hintergrund, die Firma oder wiederkehrende Anforderungen gehören in die Memory oder in einen Custom GPT. Fachliche Grundlagen kommen in angehängte Dokumente. Stilistische Vorgaben wandern in die System-Anweisungen. Der Prompt selbst konzentriert sich dann auf die konkrete, aktuelle Aufgabe.
Danach folgt das Testen. Wie verändert sich die Ausgabe, wenn bestimmte Kontextelemente hinzugefügt oder entfernt werden? Manchmal überrascht das Ergebnis. Ein Dokument, von dem man dachte, es sei hilfreich, lenkt das Modell in die falsche Richtung. Ein Memory-Eintrag, der unwichtig schien, verbessert plötzlich die Präzision enorm. Context Engineering ist empirisch, nicht theoretisch.
Die Zukunft von Kontext und Prompt
Die Entwicklung geht in Richtung noch größerer Kontextfenster und intelligenterer Kontextverwaltung. Modelle werden besser darin, relevante von irrelevanten Informationen zu trennen. Sie lernen, Kontext dynamisch zu priorisieren und bei Bedarf nachzufragen, wenn etwas fehlt.
Gleichzeitig wächst die Verantwortung der Nutzer. Je mächtiger die Werkzeuge werden, desto wichtiger wird das Verständnis für ihre Funktionsweise. Wer Prompt und Kontext nicht auseinanderhalten kann, verschenkt Potenzial. Wer beide Dimensionen beherrscht und gezielt einsetzt, holt aus denselben Modellen erheblich bessere Ergebnisse heraus.
Die Trennung zwischen Prompt Engineering und Context Engineering wird daher nicht verschwimmen, sondern schärfer werden. Spezialisierte Rollen entstehen, in denen Leute sich ausschließlich um die Gestaltung optimaler Kontextstrukturen kümmern, während andere sich auf die Formulierung perfekter Prompts konzentrieren. Beide Disziplinen ergänzen sich, aber sie bleiben getrennt, weil sie unterschiedliche Probleme lösen.
Die Informationsmenge richtig steuern
Am Ende läuft alles auf eine zentrale Erkenntnis hinaus. Zu viel Information verschlechtert das Ergebnis, weil das Modell den Fokus verliert. Zu wenig Information führt zu falschen Ergebnissen, weil dem Modell die Grundlage fehlt. Die Kunst liegt darin, genau die richtige Menge an genau den richtigen Stellen bereitzustellen.
Das erfordert Nachdenken über jedes Element des Kontexts. Braucht das Modell diese Information wirklich? Hilft sie bei der Lösung der aktuellen Aufgabe? Oder ist sie Ballast, der nur Rechenzeit kostet und Aufmerksamkeit abzieht? Diese Fragen mögen trivial klingen, aber ihre Beantwortung entscheidet über Erfolg oder Misserfolg.
Context Engineering ist deshalb keine Nebensache, die man abhaken kann. Es ist eine kontinuierliche Aufgabe, die mit jeder neuen Anforderung, jedem neuen Projekt und jeder neuen Entwicklung der Modelle neu gestellt wird. Wer das versteht und entsprechend handelt, arbeitet nicht nur effizienter mit KI-Systemen, sondern erzielt auch Ergebnisse, die andere für unmöglich halten.